Challenge Experiments and Baseline Performance
Updated on 10/9/2006 12:56 PM
We offer a set of challenge experiments, of different difficulty levels, based on the collected data. We structure the challenge tasks in terms of gallery and probe sets, patterned after the FacE REcognition Technology (FERET) evaluations. In biometrics jargon, the gallery sets are subsets of the “enrolled” data, or data on a “watch list,” and the probe sets are subsets of the query data. The gallery and the probe sets different with respect to one or more covariates that are being studied.
The data was collected over four days,
![]() Surface type (grass (G) or concrete(C)),
Surface type (grass (G) or concrete(C)),
![]() Shoe type (A or B),
Shoe type (A or B),
![]() Viewpoint (left camera (L) or right camera (R)).
Viewpoint (left camera (L) or right camera (R)).
![]() Carrying condition (With briefcase (BF), No
briefcase (NB))
Carrying condition (With briefcase (BF), No
briefcase (NB))
![]() Time (t1 tags sequences from May and
those from new subject in Nov collection, t2 tags sequences from
Nov from repeat subjects)
Time (t1 tags sequences from May and
those from new subject in Nov collection, t2 tags sequences from
Nov from repeat subjects)
Thus we have 32 possible subsets, with the number of subjects in each subject as listed in the table below. Since not every subject was imaged under every possible combination of factors, the sizes of these sets are different. We choose the largest subset, and arbitrarily choose the right camera sequences, as the gallery set, (G, A, R, NB, t1), i.e. (Grass, Shoe TypeA, Right Camera, No Briefcase, and Time t1). Rest of the subsets form the probes, testing effects of various covariates. This is depicted below using the following grid depicting the various dataset partitions. The gallery subset is in orange and the probes for the challenge experiments are in green. Note (i) the light green boxes correspond to “existing” challenge experiments and the bright green boxes correspond to the “newly added” experiments. (ii) the boxes in light yellow represent data partitions not used in the challenge experiment.
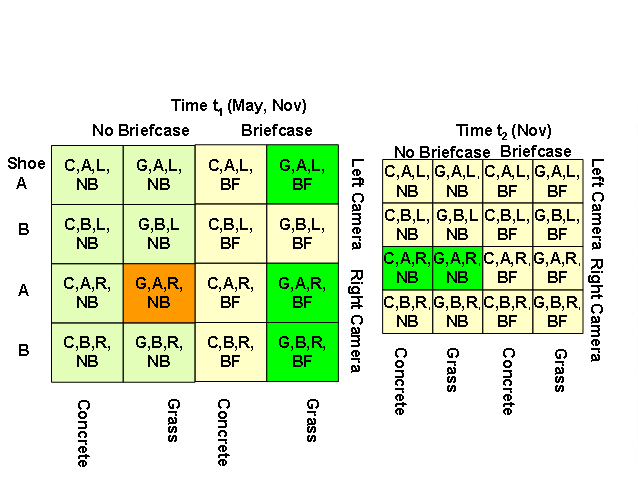
The table below lists the 11 possible experiments A through K. So far, in our analyses, we have tested the performance from May 2001 dataset and that from full dataset (May + Nov 2001), which is why we report two sets of number for the number of subjects. Also, we have considered data only from the portion of the elliptical path that is farthest to the camera for our analysis.
Gallery Set: (G, A, R, NB, t1)
122 subjects (71 subjects for May data) – Note we might have a couple of subjects with shoe type B in
the actual used gallery specifications. We did this for some subjects who walked with
only one shoe type on grass, which happened to be label as Shoe B. Since the
shoe type labeling is arbitrary, we put them in the gallery to increase the
gallery size. Identification performance is sensitive to gallery size. The
other sequences were correspondingly allocated to other probes. If you spot any
problems do let us know.
|
Exp |
Probe Sets |
Number of subjects |
Covariates Different Between Gallery and Probe |
Parameter Free
Baseline (v2.1) May data only |
Parameter Free
Baseline (v2.1) May + Nov data |
|||||
|
Total |
May data only |
PI |
|
PI |
Pv(Z-Normed) at
PF=1% |
Pv(Z-Normed) at
PF=10% |
||||
|
A |
(G, A, L, NB, t1) |
122 |
71 |
View |
87% |
|
73% |
82% |
94% |
|
|
B |
(G, B, R, NB, t1) |
54 |
41 |
Shoe |
81% |
|
78% |
87% |
94% |
|
|
C |
(G, B, L, NB, t1) |
54 |
41 |
View, Shoe |
54% |
|
48% |
65% |
94% |
|
|
D |
(C, A, R, NB, t1) |
121 |
70 |
Surface |
39% |
|
32% |
44% |
80% |
|
|
E |
(C, B, R, NB, t1) |
60 |
44 |
Surface, Shoe |
33% |
|
22% |
35% |
76% |
|
|
F |
(C, A, L, NB, t1) |
121 |
70 |
Surface, View |
29% |
|
17% |
20% |
60% |
|
|
G |
(C, B, L, NB, t1) |
60 |
44 |
Surface, Shoe, View |
26% |
|
17% |
28% |
55% |
|
|
H |
(G, A, R, BF, t1) |
120 |
70 |
Briefcase |
|
|
61% |
72% |
91% |
|
|
I |
(G, B, R, BF, t1) |
60 |
47 |
Shoe, Briefcase |
|
|
57% |
67% |
85% |
|
|
J |
(G, A, L, BF, t1) |
120 |
70 |
View, Briefcase |
|
|
36% |
48% |
76% |
|
|
K |
(G, A/B, R, NB, t2) |
33 |
33 |
Time (+Shoe, Clothing) |
|
|
3% |
6% |
24% |
|
|
L |
(C, A/B, R, NB, t2) |
33 |
33 |
Surface, Time |
|
|
3% |
6% |
24% |
|
PI: Indentification Rate, Pv: Verification Rate,
PF: False Alarm;
Parameterized version results as reported at ICPR-2002 have been superceded
by the parameter free version, as reported above
Note that we have two versions
of the baseline algorithm available: Parameterized (Version 1.*) and
Parameter-free (Version 2.*), which is why we report two sets of numbers: one
in green and the other in red. Please see the baseline
algorithm page for more details about how they are different.
We classify people in this
dataset into 3 categories according to their recognition rate. The definitions
and ID list of each class are described below:
- Easy to Identify.
Definition: the
recognition rate is no less than 80% in all experiments.
ID list: 03697
03690
03689
03687
03653
03652
03635
03633
03792
03774
03699
02291
- Moderate to Identify.
Definition: the
recognition rate is between 40% and 80% in all experiments.
ID list: 03786
03673
03667
03662
03696
03695
03684
03680
03671
03670
03603
03509
03789
03782
03778
03769
03524
03510
03508
03685
03674
03669
03636
03500
03686
03683
03678
03675
03664
03658
03775
03772
- Hard to Identify.
Definition: the recognition rate is less than 40% in all
experiments.
ID list: 03574
03532
03517
03501
03693
03700
03688
03663
03657
03591
03793
03790
03783
03771
03770
03767
03741
03648
03641
03621
03614
03523
03691
03672
03666
03516
03507
02463
03692
03682
03679
03676
03665
03521
03735
03707
03698
03643
03627
03567
03661
03659
02539
03784
03785
03681
03537
03791
03788
03787
03781
03779
03773
03766
03762
03754
03640
03637
03608
03605
03594
03563
03506
03677
03655
03634
03529
03526
03505
03545
03660
03768
03738
03629
03572
03776
03765
03694