Research Interests
My research interests are data science and system informatics with their applications in reliability, quality, energy, homeland security, manufacturing, etc. Specifically, I develop and apply sophisticated statistical methodologies and tools, integrated with domain knowledge, to tackle complex problems (e.g., modeling, prediction, design, monitoring, diagnostics, prognostics, planning, scheduling, control, etc.) in a data-rich environment and meet with challenges in a Big data era.
Methodologies
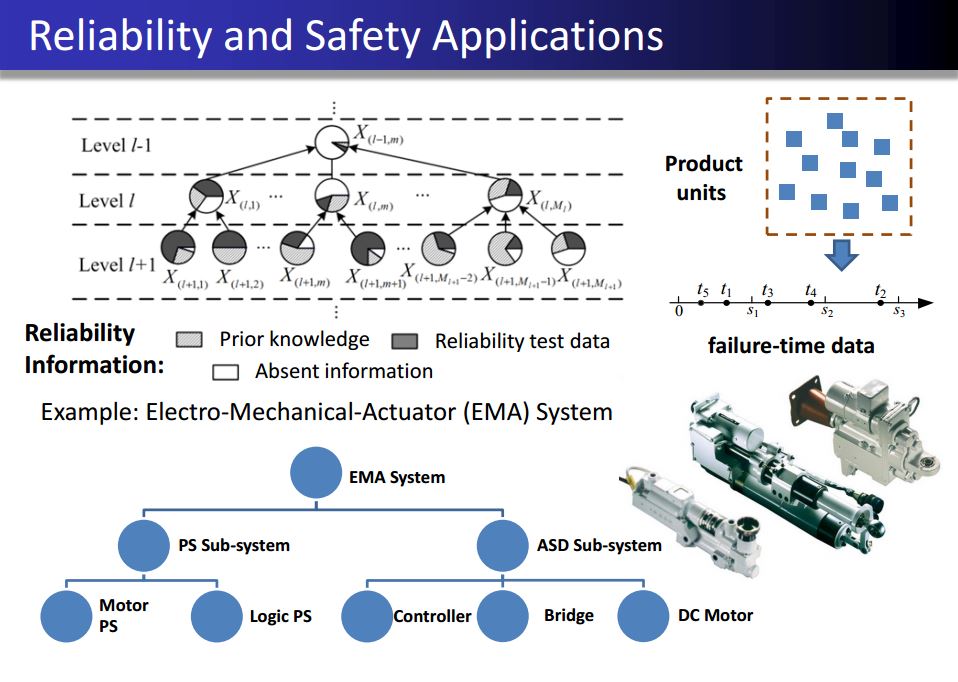
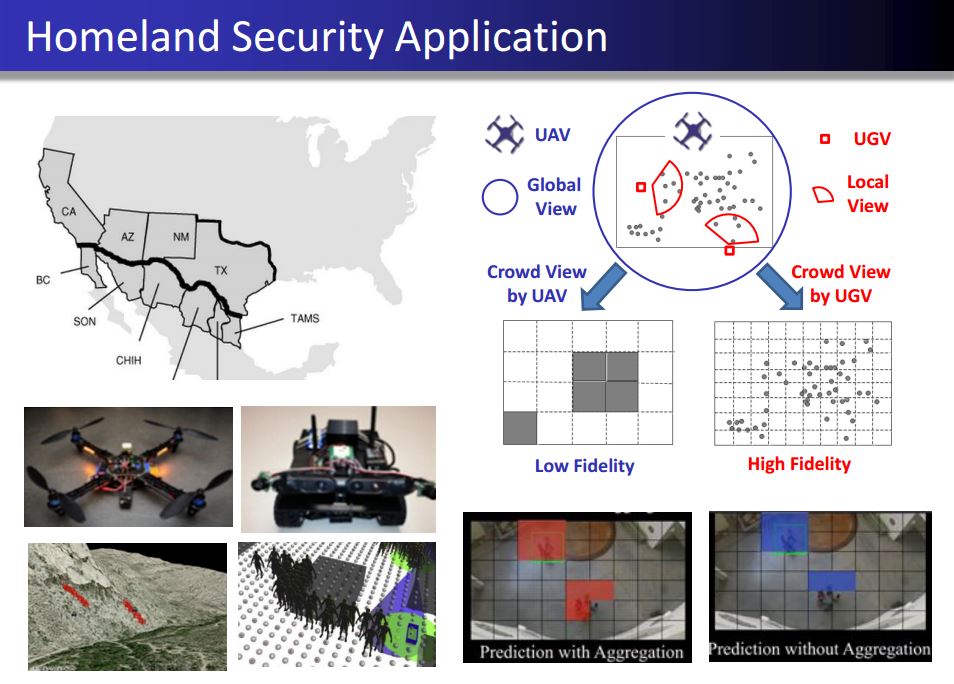
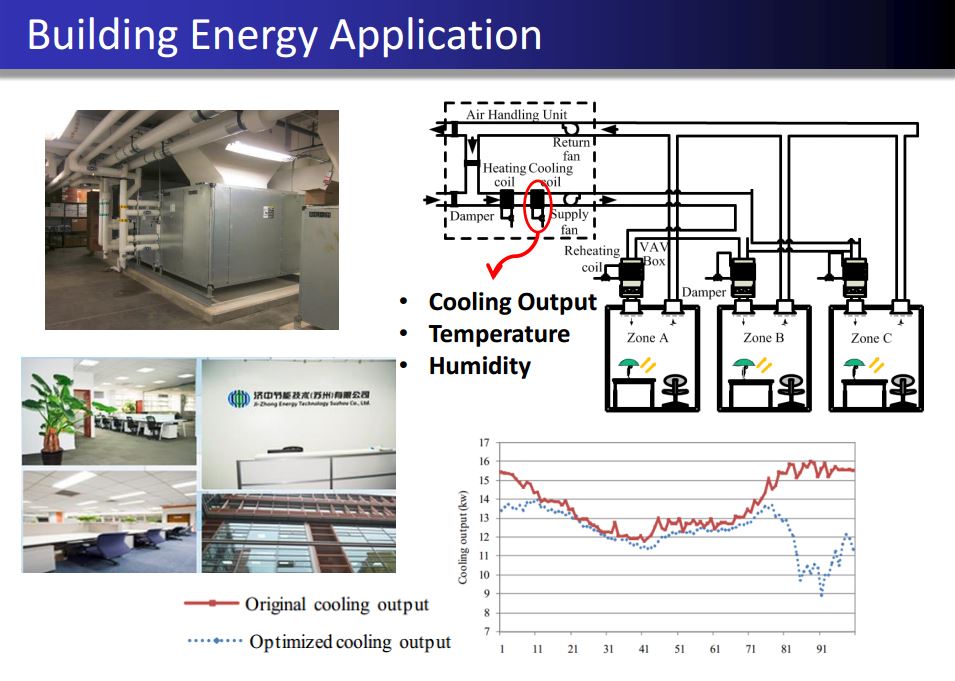
Information Fusion-based System Informatics: With the advancement of sensing technology and information storing systems, a data-rich environment has been created in many complex systems with multiple data sources available at different levels. For instance, in the reliability assessment of a typical hierarchical engineering system, multi-source reliability data (e.g., success/failure data, failure-time data, degradation data, etc.) is available at different levels (e.g., system level, component level, etc.). In the modern crowd surveillance system equipped with unmanned ground and aerial vehicles, the multi-fidelity crowd sensing data is continuously generated. To fully utilize and integrate such multi-source data for improving the system performance is a challenging task. This line of research is to develop a generic, coherent, flexible and scalable data fusion framework to improve the system performance. Some successful outcomes include the improvement of system reliability prediction accuracy and precision, the cost reduction of system reliability demonstration tests and the improvement of crowd tracking performance.
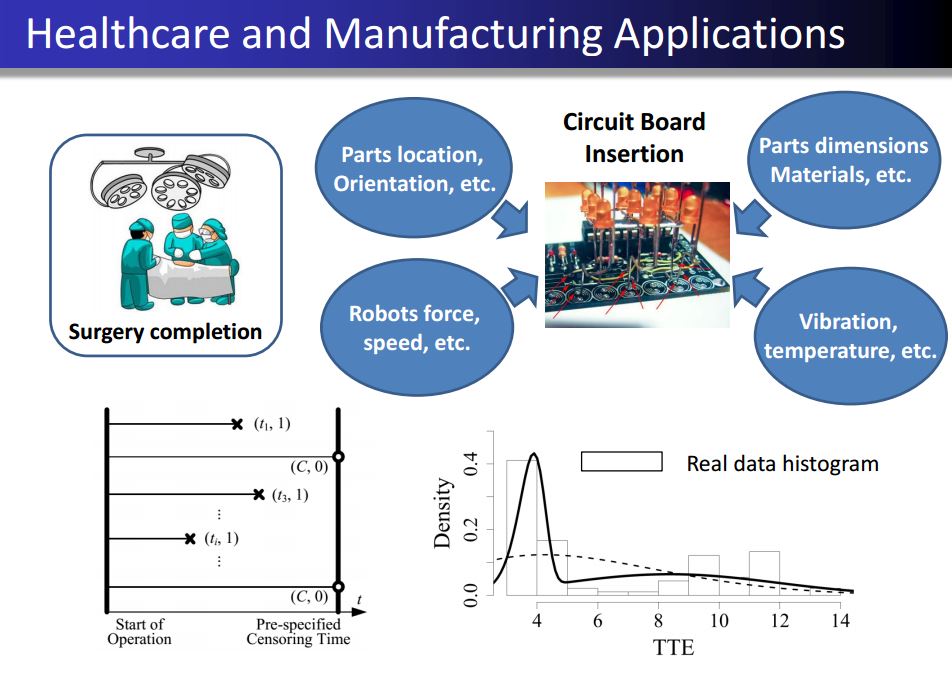
Bayesian Semi-parametric Modeling for Complex Data Analysis: Real-world data (e.g., degradation data, warranty records, quality profiles, image signals, etc.) often has complex data characteristics, such as heterogeneity, missing data (e.g., missing labels, censoring), high-dimensionality, etc. It will be beneficial and necessary to develop advanced statistical modeling and analysis tools to accommodate such data complexity for better representation, visualization, quantification, prediction, decision making, etc. Among many rapidly evolving statistical modeling tools, Bayesian semi-parametric modeling is one of the promising areas. It carries the advantages of Bayesian learning paradigm (e.g., quantifying uncertainties, incorporating prior knowledge, etc.) and further allows greater modeling flexibility with less distribution assumptions. This line of research is to build Bayesian semi-parametric/non-parametric models, intersecting with machine learning techniques and probability theory, to analyze complex data structure. Another research focus is to develop effective and efficient sampling-based estimation methods (e.g., MCMC methods) for learning such models. Some specific examples include semi-parametric hazard modeling, heterogeneous assembly data quantification and non-conjugate prior sampling.
Applications